
The Focus of this technoloty conference was Deep Learning (more on why later).
The 3 keynote talks from GTC 2015 are worth watching, they are all online. They all focused on Deep Learning.
See: http://www.gputechconf.com/highlights/2015-replays
First: Jen-Hsun Huang, Co-Founder and CEO, NVIDIA.
Second Jeff Dean, Senior Fellow at Google.
Third: Andrew Ng, Baidu, Stanford Univ, and Coursera.
Andrew’s talk was the most interesting for me. He left Google to join Baidu, in order to work on Deep Learning with GPUs supercompouters. It described among other things how his Baidu team created a brand new type of Speech Recognizer using Recurrent Neural Nets, with much less code thatn traditional Speech Recognizers, and without using phonemes as an intermediate structure!!!
The Neural Net convert the auditory phonetic segments directly into words, and does so while achieving much reduced error rates. They also increase the amount of data they train on by adding noise to the data, and then learning with the noise.
Their talks presented a kind of Brave New World future, based on GPU’s, running the gamut from cars that drive themslves to appliances that have a conversation with you.
There were also many seminars and tutorials related to GPU usage and in particular as s it applies to Deep Learning. Many of these are video streamed, and/or have PDFs associated with them for those that wish to learn on their own.
GPUs are not particularly easy to program. At the end of this talk, I will give a brief overview about how GPUs work.
A lot of the tutorials in the conference cover different frameworks that make it easier to implement DNN’s with less programming. GPU’s have many libraries that allow for fast implementation of different algorithms, such as cuBLAS for linear algebra, cuFFT for Fourier trasnforms, and cuRand for random number generators. cuDNN provides a library for accelerating Deep Neural Net algorithms.
This library is in turn used by other DNN related modular systems, like Theano.
Some of the systems are based on creating hybrid programming such as Python with GPUs. A library cuPython allows you to write Python programs that take advantage of the GPU. Matlab with GPU exists but does not perform well. Theano was a system developed by the University of Montreal (were Geofrey Hinton hangs out) with DNN’s in mind. Theano is a symbolic python based processor that extends Numpy and SciPy to use the GPU. It is kind of like an optimizing compiler within an interpreter. It is not particular intuitive, though in my opinion. But it has quite a few examples and tutorials related to DNNs. See: http://deeplearning.net/tutorial/
Another framework called Caffe that was originally implemented at the Berkeley Vision and Learning Center (BVLC) to facilitate implementation of image classification DNN based systems with GPUs. See http://caffe.berkeleyvision.org/
The use of GPU’’s in combination with Deep Learning algorithms have had very significant impact in relation to Image recognition as illustrated by the ImageNet challenge, which has re-energized interest in Neural Net algorithms as an interesting path for Machine Learning.
The following depicts the Convolutional DNN architecture that was used by Krizhevsky in 2012 to win this competition [1]

On ImageNet, it is customary to report two error rates: top-1 and top-5, where the top-5 error rate is the fraction of test images for which the correct label is not among the five labels considered most probable by the model. The following slide shows how ambiguous some of the failing results turn out to be:

Krizhevsky’s paper describes what it took computationally to do this:
“In the end, the network’s size is limited mainly by the amount of memory available on current GPUs and by the amount of training time that we are willing to tolerate. Our network takes between five and six days to train on two GTX 580 3GB GPUs. All of our experiments suggest that our results can be improved simply by waiting for faster GPUs and bigger datasets to become available.”
As a point of interest, the current Titan X GPU (a $1000.00 far exceeds the GTX580 in capability. So it will be interesting to see what results they get. A Titan X has 3072 CUDA Cores, 12 GB of memory, a base clock of 1 Ghz. In comparison a GTX580 has 512 cores, 1.5GB of RAM, and a base clock of 1544 Mhz.
They both have a 384-bit shared to global memory bus width.
In Feb 2015 Microsoft Researchers announce setting a newer record:
“To our knowledge, our result is the first to surpass human-level performance …on this visual recognition challenge…”2. Of course they also used GPU’s too achieve this.
They claim to have achieved 4.94% top-5 test error on the ImageNet 2012 which is a 26% relative improvement over the ILSVRC 2014 winner (GoogLeNet, 6.66% [3]).
The GTC2015 a streamed talk by Rob Fergus gives an excellent tutorial titled: “Visual Object Recognition Using Deep Convolutional Neural Networks” which covers in great detail the technology used to attack the ImageNet problem. The slides above were lifted from this talk.
When you install the NVIDIA GPU programming environment, you get a lot of sample programs (open source). I will provide a few demos of GPU programs. GPGPU stands for Glneral Purpose Programming Unit.’s were originally developed to do graphics well, and were funded by addicts to computer games. I will only be addressing the “General Purpose” side of things.
Some interesting visual demos are:
) deviceQuery
) particles
*) smokeParticles
In the future I would like to show some demos GPU accelerated MNIST Digit recognition and possibly Imagenet (more on this later). (see http://yann.lecun.com/exdb/mnist/ or http://deeplearning.net/datasets/.
This particular laptop is set up with one of the latest versions of the GPU GT860M (Maxwell architecture with ‘compute level 5.0’). Laptops with this chip set are uncommon, and can be somewhat painful to set up.
A GPU Memory Model is patterned to optimize an SIMD style of parallelism. Although the name of the computer model they describe is SIMT (Single Instruction Multiple Threads). Shared Memory and parallel registers within a each block (i.e corresponding to a Streaming Processor) provides this SIMD like quality. SIMT makes parallel programming much more practical.
A BLOG that I think provides a good intuition about how GPUs work conceptually can be found at: http://yosefk.com/blog/simd-simt-smt-parallelism-in-nvidia-gpus.html
This overview does a good summary of the flow of data in a GPU.
Input and output (CPU to GPU and back) is based on the througput of PCI2.0 or PCI3.0 depending on level of GPU. Movement from Global Memory to Shared Memory is based on a very wide bus.
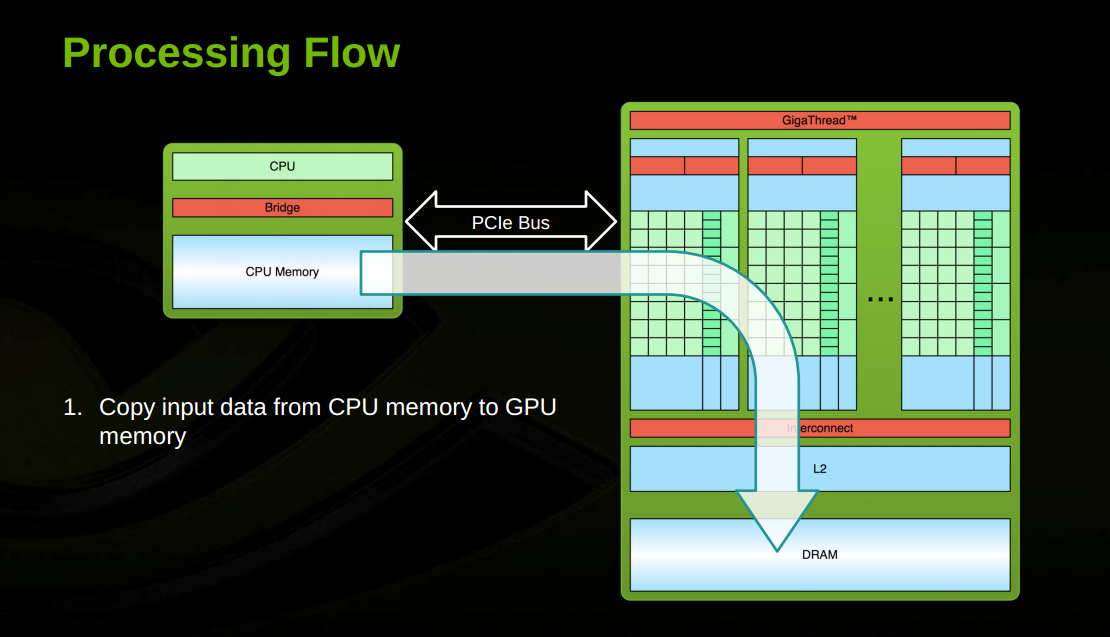
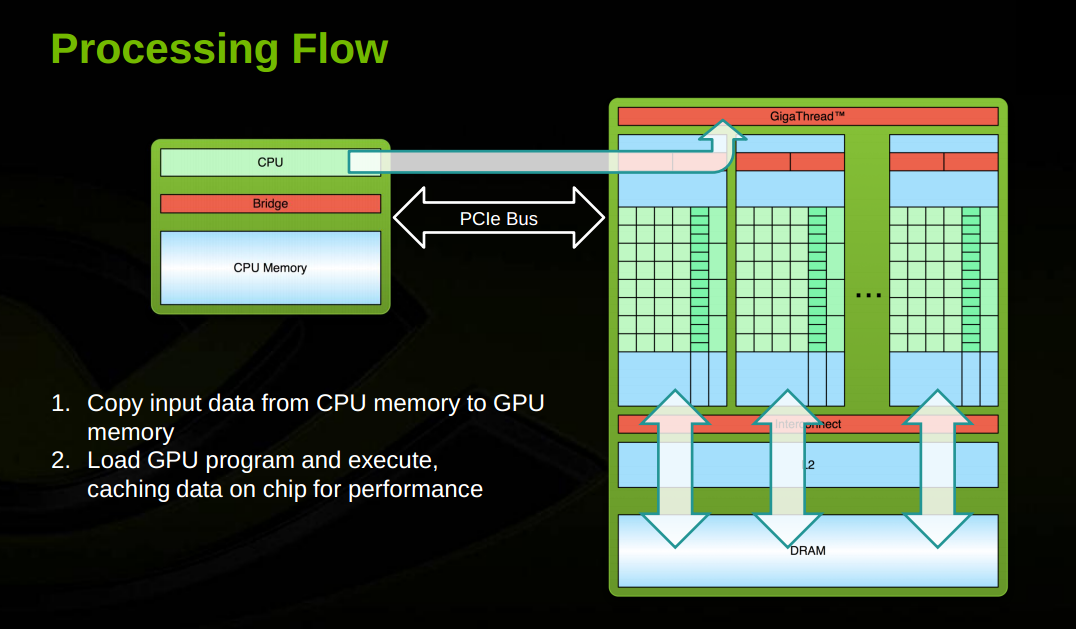
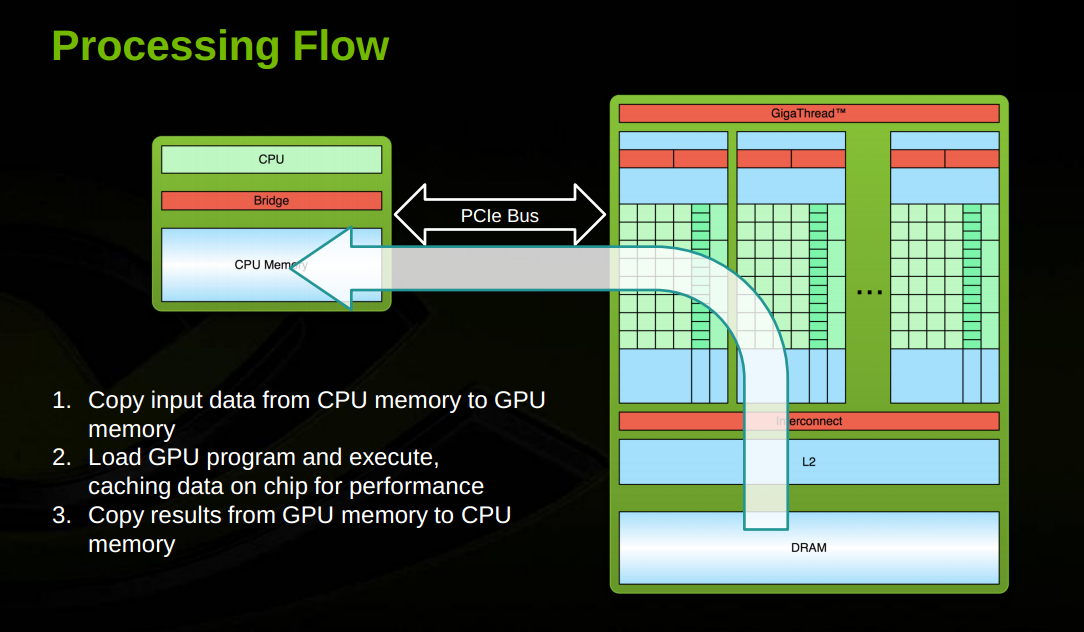
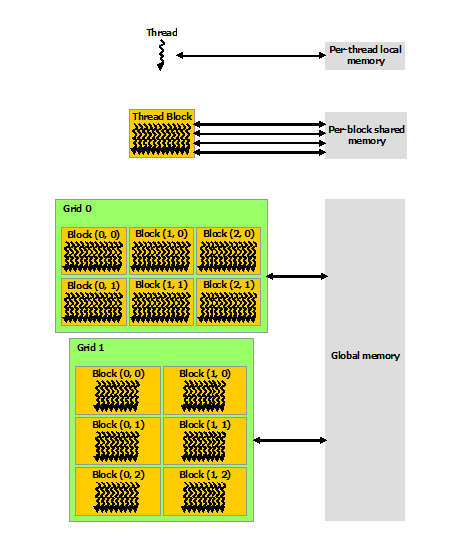
CUDA threads may access data from multiple memory spaces during their execution as illustrated by the Memory Model figure. . Each thread has private local memory.
Each thread block has:
shared memory: visible to all threads of a block (has same lifetime as a block - not shared across threads). It is also volatile across kernel calls. But it is very vast, almost as fast as registers.
global memory: Accessible by all threads
constant memory: Constant and accessed by all threads.
texture memory: Constant and accessed by all threads. Also offers different addressing modes and data filtering capability (interpolation). (explore Texture and Surface Memory).
GLOBAL, CONSTANT, TEXTURE meory are persistent across kernel calls.
Not discussed above are the register and various caches, which appear somewhat invisible to the memory programming model, but have a big effect on performance.
NVCC is the compiler for CUDA. In Linux it invokes gcc to compile for the CPU, and it generates code for the Graphics Pre-processor and creates a unified executable that gets split across both.
A GPU coprocessor (call to a parallell-execution type of function, is called with a kernel call, here are two samples kernel call definitions;
Here is a kernel call definitions that executes within a single thread but across multiple cores (SIMD style).
// Kernel definition
__global__ void VecAdd(float* A, float* B, float* C) {
int i = threadIdx.x;
C[i] = A[i] + B[i];
}
int main() {
... // Kernel invocation with N threads
VecAdd<<<1, N>>>(A, B, C); ...
}Here is a kernel call definitions that spans multiple threads and multiple cores:
// Kernel definition
__global__ void MatAdd(float A[N][N], float B[N][N], float C[N][N]) {
int i = blockIdx.x * blockDim.x + threadIdx.x;
int j = blockIdx.y * blockDim.y + threadIdx.y;
// This executes in parallel within one block (SIMD multiple cores)
// and within multiple blocks (SMs) via multiple threads.
// the N's define the boundary of the array.
// At the end of the boundary the SIMD models bifurcate.
//
if (i < N && j < N) C[i][j] = A[i][j] + B[i][j];
}
int main() {
...
// Kernel invocation dim3 threadsPerBlock(16, 16);
dim3 numBlocks(N / threadsPerBlock.x, N / threadsPerBlock.y);
MatAdd<<<numBlocks, threadsPerBlock>>>(A, B, C); ...
}Number of threads per block are limited to threads of a block are expected to reside on the same processor core and must share the limited memory resources of that core (Shared memory). On current GPUs (?), a thread block may contain up to 1024 threads.
A kernel can be executed by multiple equally-shaped thread blocks, so that the total number of threads is equal to the number of threads per block times the number of blocks. Threads get submitted by scheduler so that it can accommodate different architecture.
Note that kernel configuration across a parallel algorithm will affect performance and should be tuned to the capabilities of the processor.
Blocks are organized into a one-dimensional, two-dimensional, or three-dimensional grid of thread blocks.
Thread blocks must execute independently: they can be scheduled in any order.
This enables programmers to write code that scales with the number of cores.
Threads within a block can cooperate by sharing data through some shared memory and by synchronizing their execution to coordinate memory accesses. They can specify synchronization points in the kernel by calling the __syncthreads() which acts as a barrier at which all threads in the block must wait before any is allowed to proceed.
Access the CUDA C Programming Guide for more information.
There are two main types of GPUs, the Quadro and the GTX series The Quadro has bigger pixel depth, and is primarilly used by graphic designers, and video professionals. The GTX series is mostly used by gamers and GPGPU programmers.
The Maxwell architecture is primarilly recognized for gread advances in power efficiency. With 3.6 billion transistors it could consume a lot of power. It also adds some key features related to better supported MPI (Message Passing Interface) and Dynamic Parallelism (ability to call GPU kernels from inside GPU kernels). Note that a Mandelbrot set image computed using the latter technique was able to outperform a similar algorithm within the same GPU by 2.8X. I executed that routine on this laptop!
Diagram of Full Chip:
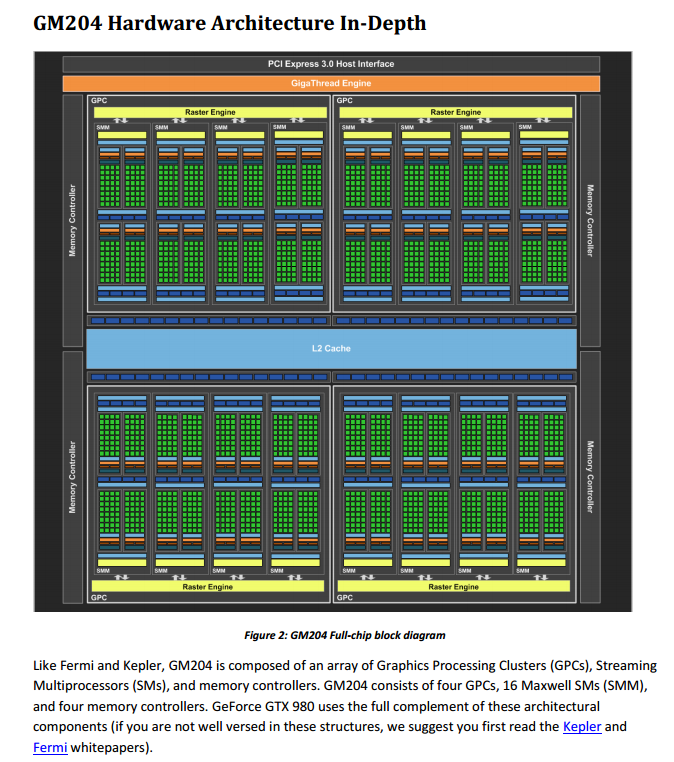
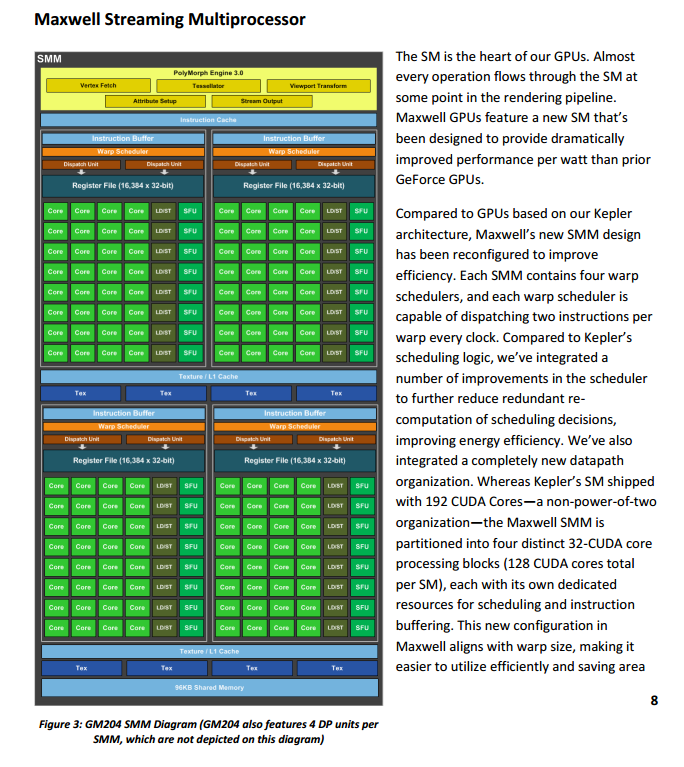
Diagram of Streaming Processor:
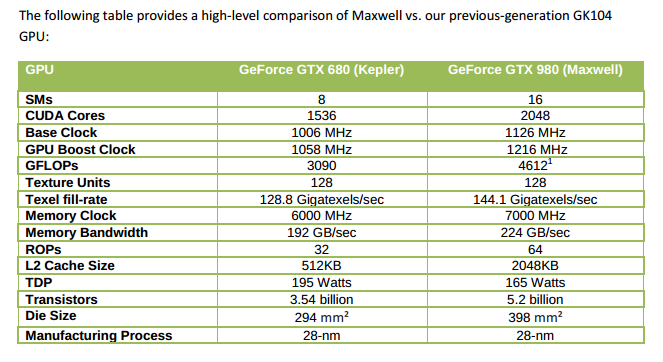
Comparison of Maxwell Architecture vs. Kepler (predecessor)
Below are excerpts from: [http://devblogs.nvidia.com/parallelforall/unified-memory-in-cuda-6/] (http://devblogs.nvidia.com/parallelforall/unified-memory-in-cuda-6/)
“Unified Memory creates a pool of managed memory that is shared between the CPU and GPU, bridging the CPU-GPU divide. Managed memory is accessible to both the CPU and GPU using a single pointer. The key is that the system automatically migrates data allocated in Unified Memory between host and device so that it looks like CPU memory to code running on the CPU, and like GPU memory to code running on the GPU.”
“CUDA has supported Unified Virtual Addressing (UVA) since CUDA 4, and while Unified Memory depends on UVA, they are not the same thing. UVA provides a single virtual memory address space for all memory in the system, and enables pointers to be accessed from GPU code no matter where in the system they reside, whether its device memory (on the same or a different GPU), host memory, or on-chip shared memory.
It also allows cudaMemcpy to be used without specifying where exactly the input and output parameters reside. UVA enables “Zero-Copy” memory, which is pinned host memory accessible by device code directly, over PCI-Express, without a memcpy. Zero-Copy provides some of the convenience of Unified Memory, but none of the performance, because it is always accessed with PCI-Express’s low bandwidth and high latency.
UVA does not automatically migrate data from one physical location to another, like Unified Memory does. Because Unified Memory is able to automatically migrate data at the level of individual pages between host and device memory, it required significant engineering to build, since it requires new functionality in the CUDA runtime, the device driver, and even in the OS kernel. The following examples aim to give you a taste of what this enables."
New Path in CUDA 6.0: Unified Memory can be used starting with the Kepler GPU architecture (Compute Capability 3.0 or higher), on 64-bit Windows 7, 8, and Linux operating systems (Kernel 2.6.18+) i.e. Not in GTX580 which is the Fermi architecture. (Currently have 6.5 in my laptop).
I think you might find this interesting. A few years back (October of 2011) we had an article at this URL: http://tasc.ucsc.edu/
“TASC is a vibrant new institute, spanning four UCSC departments that are involved in research in astrophysics and planetary sciences. Its fourteen participating faculty members make up the largest group of computational astrophysicists in the world. Building on this strength, TASC has begun a unique new interdisciplinary program in scientific computation and visualization in collaboration with members of UCSC’s Digital Arts and New Media Center. TASC is also spearheading an effort to create a Ph.D. program in high-performance supercomputing, in partnership with the Baskin School of Engineering’s Department of Applied Mathematics.”
UCSC followed up with some interesting resources related to GPU’s, as this article indicates, URL: http://news.ucsc.edu/2013/07/hyades-supercomputer.html:
“UCSC acquires powerful new astrophysics supercomputer system” NSF-funded ‘Hyades’ supercomputer is paired with a Huawei UDS petabyte storage system for data archiving and sharing. By Tim Stephens, July 31, 2013
The page more recently updated http://hipacc.ucsc.edu/, however, provides a gloomy follow on: It first mentions achievements from 2010-2014 but goes on to say: “UC-HiPACC Funding Discontinued”
“Funding has not been renewed for 2015 and beyond for the five-year-old University of California High-Performance AstroComputing Center (UC-HiPACC). UC-HiPACC’s major programs are therefore suspended. Alternative sources of funding are now being sought. Meantime, a No-Cost Extension to the grant has been approved through March 31, 2015, to support limited operations, including the pioneering AGORA research effort, preparation of a five-year report, and crafting of proposals for outside support. Pending receipt of alternative funding, some suspended programs may be resumed. For details, see UC-HiPACC press release.” and refers to this article for more detail: http://hipacc.ucsc.edu/PressRelease/UC-HiPACC-Closing-Release.html
All quite gloomy. The Director running this is Joel R. Primack with the UC High-Performance AstroComputing Center (UC-HiPACC) Department of Physics, at UCSC. joel@ucsc.edu, Cell: 831-345-8960, http://hipacc.ucsc.edu/
These supercomputer are not just one GPU but a whole cluster of them. One GPU is hard to program, a cluster of them (which typically also uses MPI (Message Passing Protocol)) is even harder.
So my question is, if we have such a powerful computer. why is the Computer Science Department not pusing to use this very valuable resource to teaching parallel programming, or to do research on DNNs? These are, of course, very timely topics.
Even if this supercomputer were not available. NVIDIA is encouraging academic institutions provide programming with GPUs, According to some of the talks I attended, access to remote GPU’s for courses can be had on a contributed basis. If this was of interest, I could look at my notes and try to research it further.
But, in addition, a very powerful GPU of current vintage, the Titan X can be bought for only $1,000.00. What is unfortunate is that the only teacher at UCSC that taught parallel computer programming was Andrea DiBlas and he has not taught this course in a long time. So we don’t have anyone to teach this important topic.
[1] ImageNet Classification with Deep Convolutional Neural Networks. Alex Krizhevsky, Ilya Sutskever, Geoffrey E. Hinton from the University of Toronto
[2] Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification. Kaiming He Xiangyu Zhang Shaoqing Ren Jian Sun from Microsoft Research; URL: http://arxiv.org/pdf/1502.01852v1.pdf
[3] C. Szegedy, W. Liu, Y. Jia, P. Sermanet, S. Reed, D. Anguelov, D. Erhan, V. Vanhoucke, and A. Rabinovich. Going deeper with convolutions. arXiv:1409.4842, 2014.